天猫双11数据是假的吗?

@Merlin 在某个回帖中推荐了一个新闻给我(不用去找那个帖子了,有毒的…)。
新闻来源: 天猫双11数据是假的? https://xw.qq.com/cmsid/20191113A032DE00
虽然我不是empiricist,但我用我还记得一点点的econometrics试试看能否证实或者证否这个新闻…
首先双11是短期的数据,受到的扰动比较大,趋势比较难以发现,所以我试试看用aggregated天猫每年的GMV来作为双11的标杆:1. 看看aggregated 天猫GMV是不是也可以被3项式拟合;2. 双11和天猫的数据拟合曲线是不是相似。
| 天猫 | 双11 | |
|---|---|---|
| 2012 | 2175 | 191 |
| 2013 | 4410 | 350 |
| 2014 | 7634 | 571 |
| 2015 | 11501 | 912 |
| 2016 | 14652 | 1207 |
| 2017 | 21086 | 1692 |
双11的数据来源: https://xw.qq.com/cmsid/20191113A032DE00
天猫的数据来源: https://www.zhihu.com/question/283956444/answer/439835660
用3次项拟合,图用Excel画的出来。

直接跳到结果:
如果用天猫每年的GMV数据,3项式拟合R^2是0.9966;用双11的数据,3项式拟合R^2是0.9983。而且可以看出拟合曲线以及residual value的正反两张图都是相似的。从这个上面来说双11的数据增长和天猫GMV的增长是吻合的,如果天猫GMV数据没有假,那么双11的数据增长没有问题。
其实双11的数据,或者说所有短期销量的数据,都是可以由商家操纵到达制定的目标的(比如通过推迟销售和预售这种手段)。所以不管阿里需要双11这一天的销量是polynomial还是exponential的增长都可以达到,但是如果需要操纵长期的数据(天猫GMV),那么就难很多。
综上,如果天猫GMV的数据没有问题,我认为双11的数据也没有问题。
以上。

应该没问题,不过他们商家为了凑当天的数据是不让退货的,只能第二天退货,我朋友就是买错了,当时不给退,昨天才退的货,感觉这样也算是在作假吧

哈哈哈~~~没想到你这么快。
鉴于很可能还有人会说天猫本身造假,什么强国经济数据都造假,我用亚马逊prime day 5年数据 3 次方拟合得到的R^2 = 0.9999。我也认为这是普遍现象而非造假~~~当然并不是给免单,凑业绩什么的洗地。

我觉得直接改数据可能性为0,毕竟这么大公司,数据一致性不是说着玩的。但是好像阿里双十一不能退货(好像有的也说能退),这个成交额明显是夸大的。
昨天看到 v2 上一个好几百楼的讨论帖,现在找不见了。

who fucking cares
@celestialforce #8 Learn some better phrases, such as :
Your brian has two parts, the left has nothing right, the right has nothing left. :)

知乎那个chenqin的观点我觉得很对,只要公司内部定了指标,那么为了完成任务肯定可以拟合出数据。只是方法的问题。直接改确实不大可能,但是有更多更好的方式,比如延长预售期、不许当天退货,锁定下单时间等等
额,之前详细写的总结在这次数据回滚中消失了… 没有备份,也懒得重写了…
大概不用数学地讲一下。
数学背景: 数据拟合的数学支撑是Stone–Weierstrass theorem。基本上任何数量的数据点(不管是finite还是uncountable),都可以被polynoimal方程完美拟合,方程power越高,拟合越好(R^2越高)。比如n个点用m次方多项式(算上intercept项)拟合,当m+1>=n时,都可以完美拟合(R^2=1);当m+1<n的时候,m+1越高,拟合越好(R^2越大)。
方法: 我看了两点,第一R^2>0.99的拟合度是否可信;第二双11的销量数据是否可信。用的方法是找到一个aggregated数据天猫GMV(假定这个数据是真实不造假的),用这个数据和双11的数据进行benchmark。
结论: 1. 天猫每年的GMV数据,3项式拟合R^2是0.9966,所以双11的0.9983,看上去是可信的(当然,严格的人可以用hypothesis test);2. 一次项,二次项,三次项的天猫和双11的拟合曲线很相似,更重要的是residual value和拟合曲线的正反值相似(同样,可以做更多的redidual value的分析,可以做更多的transformation,比如standardize啦,log啦,这些)。因此,在这两个结果上,假定这个天猫的数据是真实不造假的,我没办法说双11的数据作假了,只能接受双11没做假这个前提假设。
碎碎念: 当然,因为天猫的数据需要审计,所以每年的GMV数据应该不会造假,但是可以用accounting和operation的方法进行调整,已到达避税的目的。但是大规模造假应该不可能。
双11是短期数据,可以调整的方法更多,比如通过预售啦, 短期incentive啦,推迟结算啦,这种做法把之前几个月和之后几个月的demand在双11这一天进行释放。但是从之前的数据分析看来,天猫双11的增长和天猫每年的GMV增长是吻合的,并不能说双11作假了。或者可以说,如果天猫每年的GMV没有作假,那么双11的数据也没有作假…

大陆的大数据几乎没有哪个是真的

@asdfgh #14
哇,多谢大拿,撒花:)
补上之前的讨论
背景知识
数学分析中有一个Stone–Weierstrass theorem,它表明任何连续曲线都可以用多项式来逼近… 所以多项式power越高,逼近效果越好(R^2越大)…
然后如果有n个点需要用(m-1)次的多项式曲线来逼近(加上intercept,一共有m个常数)。
-
如果n<m,那么有多个polynomial曲线可以完全拟合这n个点(R^2=1)。
-
如果n=m的时候,相当于用n个方程来解m个常数,这个时候只有一条曲线(如果degree of freedom等于n的话)可以完全拟合这n个点,所以R^2=1。
-
如果n>m,相当于解一个minimization问题(square root 或者是 absolute value的minimization),这个时候R^2<=1;当然,当m越大的时候,逼近越好(R^2越高)… (比如在双11的例子中,你会看到点越少,三次方程拟合越好(R^2越大))
双11数据辨伪思路
单看双11的拟合R^2,在我看来没有什么意义。如果需要推测双11的数据是否造假,需要一个真实的非造假的benchmark。我选的是天猫的每年GMV。两个原因:1. 双11是天猫的,最终销售额需要计入天猫每年的GMV中;2. 双11的销售量是短期的,而天猫的GMV是aggregated的长期数据,长期数据比短期数据更难造假(毕竟上市公司的年审计还是很严格嘀,造假比较难,成本比较大)。
我的检验方法有一个前提【假设天猫每年的GMV是真实未被操纵造假的】。当然,如果你要说用accounting或者operation的方法也可以操纵每年的GMV,我也承认没错,所有的商业数据都可以操纵;但是和短期数据比起来,操纵对长期数据的影响来说更小。
假定天猫的数据是真实的,如果双11的数据和天猫的数据behave in the same fashion。那么我很难证明双11的数据是假的,只能接受双11的数据没有被操纵这个前提假设。
正文讨论解释
正文中我写了两个目的:
(1). 看看aggregated 天猫GMV是不是也可以被3项式拟合;
第一个目的是为了看看双11的R^2在0.99这个值是不是可信的。通过看天猫的数据R^2也在0.99附近(ref:正文第一个图),所以我觉得双11的数据在0.99附近没有问题。
(2). 双11和天猫的数据拟合曲线是不是相似。
我在正文中指出“拟合曲线以及residual value的正反两张图都是相似的”。特别是residual value的正负值在不同年份,天猫的数据和双11的数据都可以一一对应。所以我觉得双11的数据“数据增长和天猫GMV的增长是吻合的”。当然,可以更科学地去做redidual分析,或者用log等变化多做几次分析,有兴趣的人自己去看看…
结论,如果天猫GMV的数据没有问题,我认为双11的数据也没有问题。
最后,补两张线性逼近和二次逼近的图。数据进行了standardize,方便比较天猫和双11的数据。
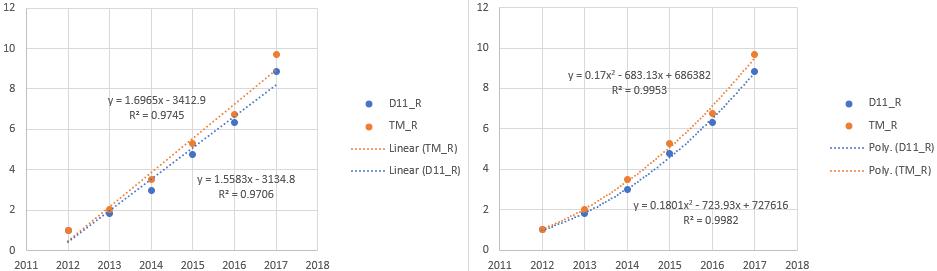
那这篇论文 make sense 吗?
https://www.solidot.org/story?sid=62634

就看你怎么理解了
销售额本来就是还没开始就定好的
然后分解任务,KA店铺都有销售量要求的,不够要刷够
第二天,这些注水的销量再进行退货退款
大家当游戏看好了 不用较真

只知那几天,小区门卫大箱,小箱一堆堆的,各家各户都有收获。淘宝在打击假货上,是有成绩的。
我是希望都过得好的,人饱去旅游,开眼界,思自由的。:)

哈哈哈,我想说两条 一、从逻辑上来讲,完美拟合多项式,甚至完美拟合线性函数,都不能说明造假。 二、从常识上判断是否造假,在这个节骨眼,不用看数字我都知道他一定造假。
@小二 #17
翻了一下原paper,https://bmcmedethics.biomedcentral.com/articles/10.1186/s12910-019-0406-6
Again,我个人不是empiricist,学过相关课程,但是不在做前沿研究,有做宏观或者计量的大拿欢迎提供更专业的意见…
首先看COTRS 2017 data,这个是aggregated的每年数据。7个数据点2此项拟合可以达到>0.999,还是很高的,但是不能排除可能性。文章的这段discussion非常好
The R-squared statistic can be difficult to interpret correctly. It is problematic to apply a formal statistical significance test to this data to determine whether it is too close to a quadratic curve, primarily because the behavior of structural growth in an industry, especially one involving as many contingencies as voluntary organ transplantation, is difficult to quantify. For this reason the same measures of closeness of fit were calculated for comparable data for 50 other countries from the Global Observatory on Donation and Transplantation (GODT) database.
在双11的例子中,我可以用天猫的数据(毕竟需要第三方审计满足上市公司的信息披露要求)作为benchmark,开判断双11数据的准确度。但是这篇文章找不到中国真实可信的benchmark的数据,所以用了其他国家的数据做benchmakr,然后发现中国器官移植数据的数据过于标准了…
It was found that when fitted to quadratic equations, every other country was between one and two orders of magnitude further away from the perfect R-squared of 1 compared to China. Of all other countries, the closest R-squared was 1.30% away from a perfect 1, with others ranging down to 99.9% away from 1; China’s three values ranged between .112% to .0478% away from 1. It was further discovered that the mean squared errors of China did not conform to the pattern exhibited by all other countries.
当然,后面作者还用COTRS 2017 data做了一些robustness tests。我看来这个COTRS 2017 data数据的确有点可疑。
后来,作者还pick up了一些Central Red Cross data的数据,这个是细化的短期数据,有更高的variability。作者讨论了5个不同寻常的数据点,作者认为是manipulation。有这种可能,但是manipulation实在是很难证明的,也可能有其他解释(比如数据平时可能遗漏,在年末审计的时候被找出来更正),我个人对作者对这一个Central Red Cross data数据的讨论存疑(至少还需要找其他benchmark来比较)。
作者最终结论:
The first is that the unusual and anomalous features in the data are due to deliberate human intervention. We believe this is the only plausible explanation for the qualities identified in the COTRS, and central and provincial Red Cross data, which include mirroring of quadratic formulae, stubborn adherence to arbitrary ratios, anomalies that abrogate the mathematical integrity of data series, unsubstantiated growth patterns, and other irregularities. It is difficult to imagine how such data from three sources could have come to possess these qualities if not for deliberate, ongoing and imperfect human intervention.
The second is that this intervention could not have been piecemeal or without forethought.
同意第一个,毕竟数学统计分析看上去plausible,但是第二个结论有点想当然,不是用数据在说话。
--
@笑翻江山 #19
淘宝假货还是很多的,天猫少一些…
@rrrr #20
只要用没有造假的真实benchmark进行对比,假的数据就很容易被发现的… 从数据上来说,从常识来说(上市公司的数据需要通过第三方审计,所以造假的成本很大,因此天猫的年数据应该是真的;在此前提下,双11的数据也应该是真的),我认为双11的确没有造假…
@Merlin #21
“sorghum harvest” 这个梗很隐秘啊,我之前看的时候怎么都想不通,后来搜到其他人的解释才明白… 然后去搜了相关报道,恶心了半天…